StrataMail Parsing, Routing & AI: Conditions, Actions, Routing
Feature Deep-Dive
Every condition, every action, every routing rule — explained for evaluation.
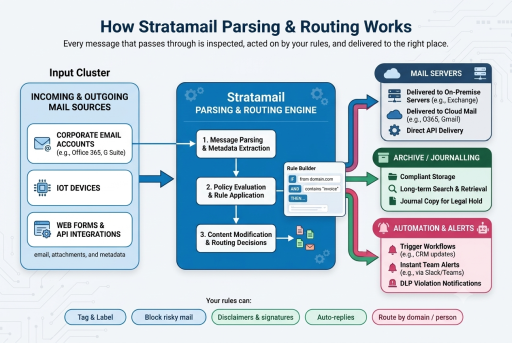
StrataMail Parsing, Routing & AI is built around rules: small, plain-English statements that say "when these conditions are true, take these actions." Rules are organized into groups that run top-to-bottom. Each rule and each group has its own continue-or-stop control for when it applies AND when it does not — enabling precise pipelines.
Rules can target direction (incoming, outgoing, internal, unknown), be scoped to everyone, one domain, or specific addresses, and optionally operate only on a schedule (chosen days and time windows).
13 Condition Types
A rule applies only when all of its conditions match (AND logic). Exceptions
can be added to skip a rule when any exception condition matches. Text-based conditions support
four match modes: contains, wildcard (* ?),
exact, and regular expression.
| Condition | What It Checks |
|---|---|
| Direction | Incoming / outgoing / internal / unknown |
| Message type | New, reply, or forward |
| Sender address | The From address |
| Recipient address | Any recipient |
| Subject | The subject line |
| Message body | The body text |
| Header | A named header's value |
| Attachment filename | e.g. *.exe |
| Attachment type | e.g. application/* |
| Attachment size | Any attachment at or above a size |
| Message size | Whole message at or above a size |
| Recipient count | At least N recipients |
| Sending rate | More than N messages within a time window |
10 Action Types
When a rule applies, its actions run in the order you have listed them. Disclaimer, signature, and auto-reply text supports placeholders that fill in per-message and per-user details — sender name, title, subject, dates, domains.
| Action | Effect |
|---|---|
| Change subject | Add text to the front or end of the subject |
| Block message | Reject (notify sender), silently drop, or temporarily fail |
| Add / remove recipients | Add To / Cc / Bcc, remove recipients, or move all to Bcc |
| Add / change a header | Add, set, or remove a named header |
| Append a disclaimer | Add disclaimer text (with de-duplication) |
| Append a signature | Add a signature, personalized per user |
| Filter attachments | Strip attachments by name, type, or size |
| Compress attachments | Zip attachments above a size |
| Automatic reply | Send a one-per-window auto-response |
| Send to automation platform | Hand the message event to your AI / automation workflow |
Routing
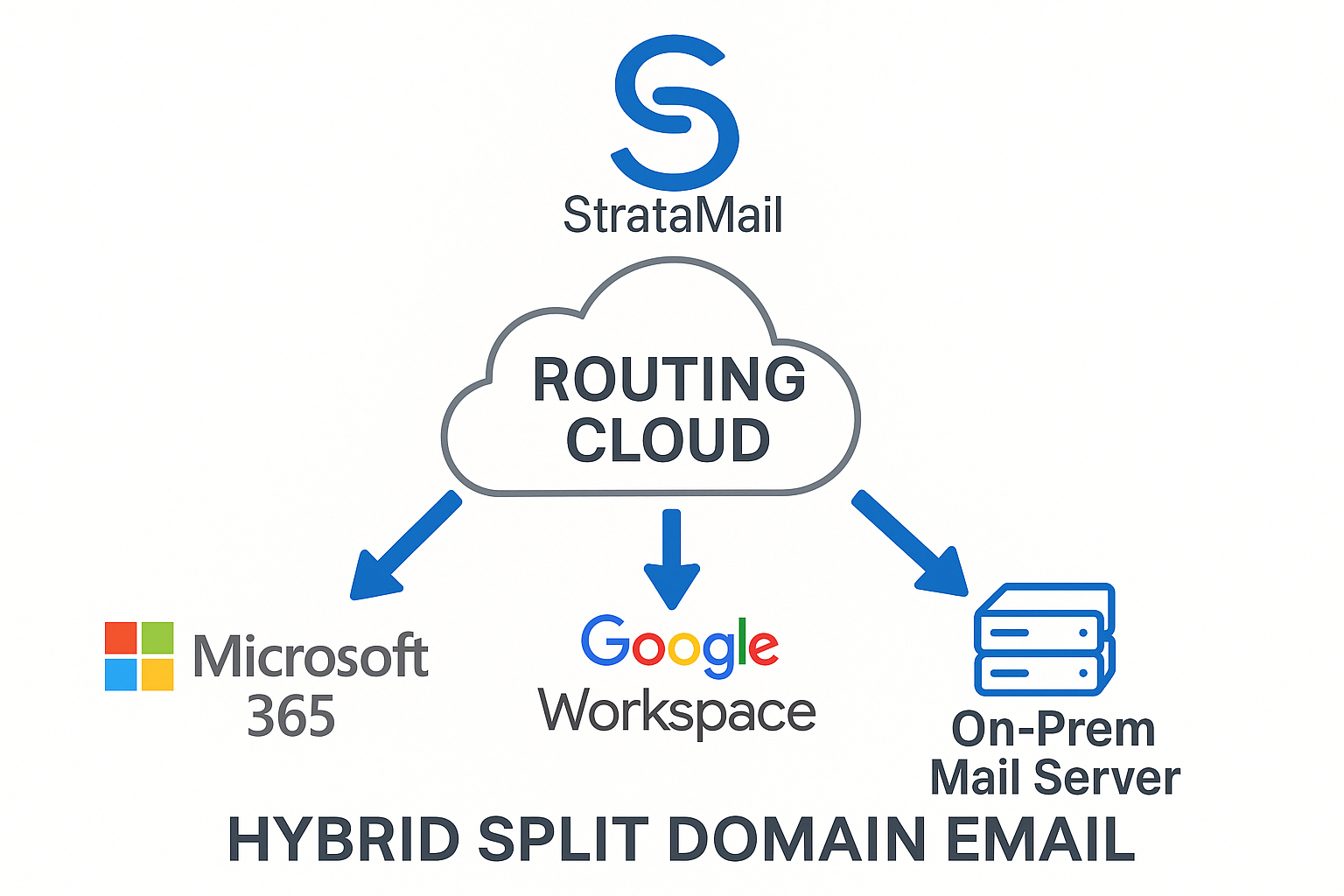
Each domain you handle can be routed to a specific destination server, and you can override routing for a single address — send one person's mail to a different server than the rest of their domain. Routing entries are ordered and managed in the Domains & Routing section of the console. A blank destination means the domain follows its normal mail records.
Common deployment patterns include hybrid Microsoft 365 / Google Workspace setups where some users live on each platform, split-domain configurations during migration, and per-team isolation where executive mail routes to a different server than general staff.
Rule Sections
General-purpose rules — any mix of conditions and actions — live under Policy Rules. In addition, each common single-purpose action has its own simplified section, so a focused rule can be built without working through the full editor. Every action the engine supports is reachable either through Policy Rules or one of these sections:
- Policy Rules — general-purpose rules with the full 13 conditions and 10 actions
- Tagging Rules — flag external mail, mark suspected phishing, or label messages by topic
- Blocking Rules — reject, silently drop, or temporarily defer messages that break policy
- Routing & Copy Rules — add or remove recipients, or BCC a journal mailbox or a manager
- Header Rules — add, set, or remove named headers for routing hints and classification
- Disclaimer Rules — simplified disclaimer management with de-duplication
- Signature Rules — simplified signature management with per-user personalization
- Attachment Rules — strip attachments by name, type, or size, or compress oversized files
- Autoresponder Rules — simplified out-of-office and acknowledgement responses
- Automation Rules — hand qualifying messages to your automation workflow for parsing and extraction
Supporting Features
Quick Setup
Guided plain-language recipes for the most common tasks — tag external mail, block risky attachments, add a disclaimer, keep a journal copy, send an auto-reply, flag keywords, manager BCC. Each recipe creates a complete, live rule.
Rules Tester
Paste a sample message and see exactly which rules match and what they would change, without sending anything. Critical for validating changes before they hit production mail flow.
Templates
Reusable disclaimer and signature text with placeholders that fill in per-message and per-user details automatically.
User Attributes
Per-person details that personalize templates — name, title, contact information, custom fields specific to your organization.
Activity View
Live view of recent processing — what messages went through, which rules fired, what actions ran, what routing was applied.
Per-Person Personalization
Signatures and disclaimers automatically pull each sender's own name, title, and contact details — one template, accurate per-user content.
Delivery & Reliability
- Mail keeps flowing even if rule processing is interrupted — the platform never holds up email
- Automatic replies and automation hand-offs happen asynchronously, so they never delay delivery
- Changes made in the console take effect within seconds
- Inline enable / disable on every rule and every group
- Reorder, clone, and move rules between groups — all changes reflect in live processing immediately
AI Handoff Detail
The Send to automation platform action is the integration point between the sequential email rules engine (conditions and actions) and your AI workflows. When a rule with this action matches, the platform passes the message event (headers, body, attachments) to a downstream workflow that can parse structured text from the email payload, extract table data from inbound email, and return extracted email body data as JSON to your API, database, or n8n workflow. From there a workflow can:
- Transcribe audio attachments using cloud or self-hosted speech-to-text with multi-language detection
- Extract structured data from invoice, order, ticket, or form-submission emails using LLM reasoning over your custom schema
- Classify and prioritize support emails by category, sentiment, and urgency
- Draft starter replies using LLM generation tuned to your tone and templates
- Route results to your stack — CRM, ticketing, accounting, custom databases, or internal applications
Organizations that cannot send content to cloud AI services can deploy local LLM processing on their own VPS or Proxmox infrastructure — message content never leaves your environment. See Local LLM Automation for the private-deployment model.
Automation & Data Extraction
Downstream of the rules engine, automated email data extraction turns unstructured messages into clean, structured records. The engine reads lines and fields from raw PDF and text streams in the message body and attachments, extracts table rows, and pushes clean JSON arrays into external databases, CRMs, ERPs, ticketing, and accounting systems — using n8n orchestration to manage the pipeline.
- n8n email automation workflow — open-source orchestration with 400+ connectors, visual workflow design, branching logic, retries, and logging
- Structured extraction — pull invoice numbers, order details, SKUs, line items, and dates from email body text and PDF attachments into a schema you define
- Clean output — deliver results as JSON arrays to an API endpoint, webhook, or direct database write
- Voicemail attachment transcriber — self-hosted multi-language speech-to-text that never sends audio to third-party services
- Reliable execution — the workflow layer handles authentication, error handling, and retry logic when downstream systems are unavailable
Common pipelines include order intake, support-ticket creation, invoice and document processing, and lead capture into a CRM — each built as a rule that hands matched messages to the automation layer.
Migrating From a Legacy Classification System
Many organizations arrive here with a legacy email classification or routing system — one large funnel of hard-coded logic, thinly documented, that only the original developers fully understand. The platform is configured around what you already have, so the migration is a mapping exercise, not a rebuild:
| What you have today | What it becomes here |
|---|---|
| One large classification "funnel," thinly documented | A set of named, readable rules — each one visible, testable, and owned |
| Categories / destination operators (claims, recoveries, invoices...) | One routing rule per category: conditions → tag/copy → deliver to that team's queue |
| Inbox ownership spreadsheets ("who owns what") | Rule scoping: per inbox, per domain, per person — ownership is the configuration |
| Sender/recipient-driven sorting logic | First-class conditions on sender, recipient, and direction — no parsing tricks needed |
| Database lookups when the system "can't work it out" | An automation hand-off step: query your system of record, then route on the answer |
| Hard-coded logic only the original developers understand | Plain-English rule summaries anyone can audit; a built-in tester for safe changes |
| Big-bang cutover risk | Inbox-by-inbox migration: run in parallel with the legacy funnel, compare, then widen |
What Discovery Looks Like
We deliberately do not start by reverse-engineering legacy code. The faster, cleaner path runs through the people who own the work:
- Inbox ownership map. The addresses, who owns each, what arrives there, and where it must land. Your operations staff usually know this better than any document.
- Category inventory. The destination categories the work must reach, and the record each must create downstream.
- Lookup needs. The cases where routing depends on data in another system, so the enrichment steps are designed up front.
- Constraints. Hosting requirements (your cloud, a private instance, or our hosting), data residency, and retention periods — the deployment is configured to your policy, including fully private processing where message content never leaves your infrastructure.
- Pilot rules. We configure one or two inboxes' worth of rules, your team tests them against real sample messages in the built-in Rules Tester, and we expand from what works.
Two technical leads on your side plus the inbox owners are typically all that discovery requires; sessions are structured around the ownership map, not around legacy code walkthroughs. Discovery converts the items above into the configuration blueprint the build is scoped from: the validated inbox-ownership map, the category inventory with its downstream records, the enrichment design, documented deployment and data-residency decisions, and pilot rules demonstrated against your real sample messages — so your team sees the routing behave before anything goes live.
To prepare, expect us to ask: which inboxes and addresses are in scope, and who owns each? What are the destination categories, and what record must each create? When the current system cannot classify something, what happens — and what data would have resolved it? Which systems must the solution feed or query? Where must the data live, and how long must it be kept?
Send us your inbox-ownership map ahead of the first session and we will arrive with draft rules already written against it.
Ready to See It Run?
Request a console walkthrough — we will demonstrate rule building, the Rules Tester, per-domain routing, and the AI handoff flow against scenarios from your environment.